
VERBETERD YOLOV3-ALGORITME voor detectie van de veiligheidsstatus van pantografen
2022-08-02 09:13Abstract: De stroomafnemer is een cruciaal onderdeel dat het rollend materieel verbindt met het elektriciteitsnet, dus de veiligheidsstatus van de stroomafnemer is essentieel voor een soepele en stabiele werking van het rollend materieel.
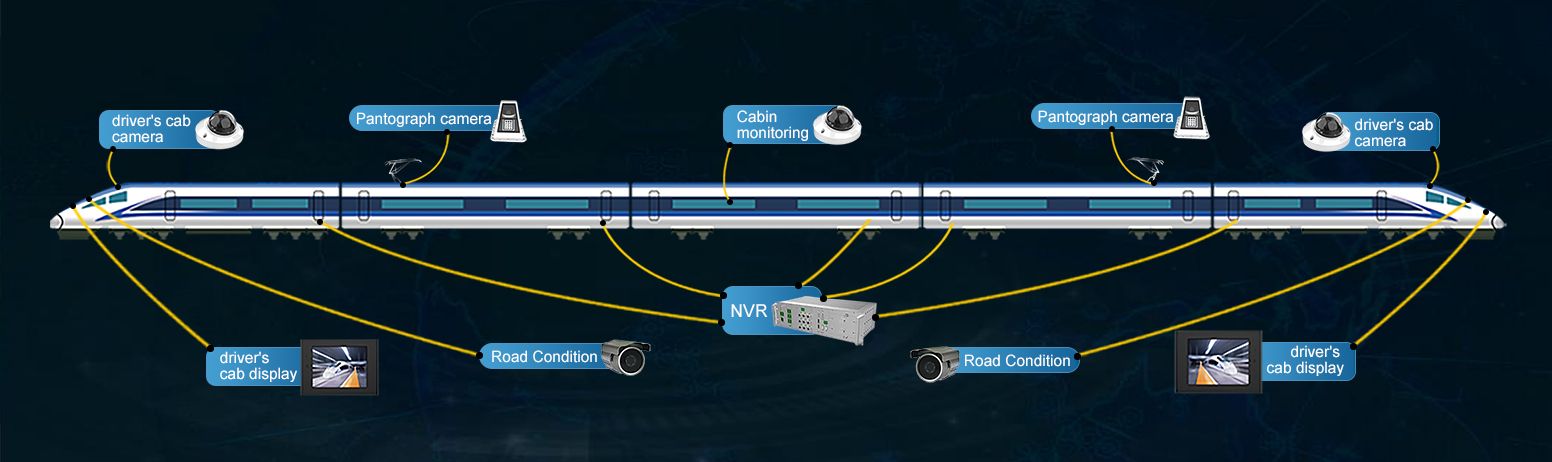
In dit artikel wordt de veiligheidsstatus van de stroomafnemer in real-time gemonitord door het videobeeld van de pantograaf, bewaakt door het videobewakingssysteem aan boord, frame voor frame te analyseren, door aanpassing van het YOLOV3-doelherkenningsalgoritme dat veel wordt gebruikt in de industrie om structurele afwijkingen, vonken en het tegelijkertijd binnendringen van vreemde voorwerpen in de stroomafnemer. Experimenten hebben bewezen dat een enkel kanaal 40 fps kan bereiken op een ingebouwde intelligente analyseserver van Tienuo. De uitgebreide detectienauwkeurigheid mAP@0.5 kan 98% bereiken, waardoor real-time en relatief nauwkeurige detectieresultaten worden bereikt.
1. Intelligente bewaking van stroomafnemers
De typische algoritmen voor doelherkenning op basis van deep learning zijn tweetrapsalgoritmen zoals het Faster R-CNN-algoritme en eentrapsalgoritmen zoals het YOLOV3-algoritme. Het YOLO-algoritme hoeft het kandidaatframe niet vooraf te berekenen in vergelijking met het R-algoritme. CNN-netwerk, dat de rekeninspanning vermindert en een hogere rekensnelheid kan bereiken. En het YOLOV3-algoritme verbetert de tekortkoming van multi-schaaldetectie van de vorige generatie van het YOLO-algoritme door drie takken in het herkenningsnetwerkgedeelte te hebben, die het probleem van doelherkenning op drie schalen aankunnen: klein, middelgroot en groot. Bovendien heeft het YOLOV3-algoritme betere technische ondersteuning en wordt het in industriële eer gebruikt in een groot aantal toepassingen. Daarom, in dit document,
2. Algoritme voor het detecteren van de veiligheid van de stroomafnemer
2.1 Doelonttrekking
Detectie van de veiligheidsstatus van de stroomafnemer kan worden onderverdeeld in detectie van afwijkingen in de pantograafstructuur, detectie van pantograafbrand, detectie van binnendringen van vreemde voorwerpen, enz. Onder hen kan de afwijking van de pantograafstructuur worden onderverdeeld in vervorming van de koolstofschuifplaat, kanteling, linker en rechter boeghoekbreuk, linker en rechte boeghoek ontbreekt, enz. De standaard, abnormale toestanden worden weergegeven in figuur 1B-F.

Figuur 1 Veiligheidsstatus en algoritmelabelingsnormen voor stroomafnemers
Om het algoritme voor doelidentificatie te gebruiken, moet eerst het identificatiedoel worden geabstraheerd om de veiligheidsstatus van de stroomafnemer te detecteren. Het geabstraheerde identificatiedoel wordt getoond in figuur 1. De stroomafnemers in normale toestand en abnormale toestand zijn uniform gelabeld. De doelen zoals boegschijf en boeghoek in normale toestand en boegschijf en boeghoek in abnormale toestand en vonken en vreemde voorwerpen zijn gemarkeerd. Vervolgens worden de gelabelde gegevens in een uniform model geplaatst voor training om alle veiligheidsstatussen van stroomafnemers in één keer te identificeren.
2.2 GAN neurale netwerkgebaseerde dataset dataverbetering
Nadat we het detectiedoel hebben gedefinieerd, moeten we onze eigen gegevensset over de veiligheidstoestand van de stroomafnemer bouwen om de noodzakelijke kenmerken van de gegevensset voor de verschillende statussen van de stroomafnemer te leren met behulp van deep learning-methoden. De dataset die nodig is voor de constructie van het algoritme in dit artikel is onderschept uit de all-weather pantograafvideobewaking van verschillende modellen. Om de invloed van de omgeving op de gegevenskarakteristieken te verminderen, wordt tijdens de voorbereiding van het gegevensmateriaal volledig rekening gehouden met de werkomstandigheden zoals verlichting, occlusie, bewolkte dagen, regen en sneeuw, in- en uitstappen, enz. De storingsstatussen van de stroomafnemer in de dataset zijn ook allemaal afkomstig van de videobewakingsbeelden wanneer de stroomafnemerstoring optreedt in de primaire vorm van de motortrein.
Gezien het feit dat sommige fouttypes minder vaak voorkomen in werkelijke bedrijfsomstandigheden, wat kan resulteren in onvoldoende gegevensvoorbereiding. De onbalans tussen de categoriegegevens zal een aanzienlijke invloed hebben op het effect van doelherkenning, dus dit artikel gebruikt een GAN-methode voor gegevensverbetering op basis van een neuraal netwerk voor verschillende gegevenscategorieën.
Generative Adversarial Network GAN bevat twee modellen, een generatief model en een discriminerend model. De taak van het generatieve model is om instanties te genereren die er van nature realistisch uitzien en vergelijkbaar zijn met de oorspronkelijke gegevens. De taak van het discriminerende model is om te bepalen of een bepaald voorbeeld inherent echt of kunstmatig vervalst lijkt.
Het kan gezien worden als een zero-sum game. De generator probeert de discriminator voor de gek te houden en de discriminator probeert zich niet voor de gek te laten houden door de generator. De modellen worden getraind door alternatieve optimalisatie en beide modellen kunnen worden verbeterd. Op basis van deze twee netwerken wordt het Generator-netwerk gebruikt om het beeld te genereren, dat een willekeurige ruis z ontvangt en het beeld veroorzaakt door deze ruis, genoteerd als G(z). De discriminator is een discriminerend netwerk dat bepaalt of een afbeelding is"echt"of niet. De invoer is x, x vertegenwoordigt een afbeelding en de uitvoer D(x) vertegenwoordigt de waarschijnlijkheid dat x een werkelijke afbeelding is. Als het 1 is, betekent dit een 100% nauwkeurig beeld, en als de uitvoer 0 is, is het onmogelijk om een nauwkeurig beeld te zijn. Vervolgens wordt het GAN-netwerk schematisch weergegeven in figuur 2. x is de daadwerkelijke gegevens en de nauwkeurige gegevens komen overeen met de Pdata(x)-distributie. Z is de data met ruis, en de data met ruis komt overeen met de Pz(z)-verdeling, zoals een Gaussiaanse of een uniforme verdeling. Vervolgens wordt de bemonstering gedaan vanuit de luidruchtige z, en de gegevens x=G(z) worden gegenereerd na het passeren van G. Vervolgens worden de daadwerkelijke gegevens ingevoerd in de classificator D, en een sigmoïde functie volgt de gegenereerde informatie, en de uitvoer bepaalt de categorie.

Figuur 2 Schematisch diagram van het GAN-netwerkprincipe
Beeld-naar-beeld-transformatie is een klasse van visuele en grafische problemen waarvan het doel is om mappings tussen input- en outputbeelden te leren met behulp van een trainingsset van uitgelijnde beeldparen. Ons doel is om de G:X-mapping te kennen → zodanig dat de distributie van foto's van G(X) niet te onderscheiden is van de distributie Y met behulp van vijandig verlies. Aangezien deze mapping zeer onderbeperkt is, koppelen we het aan een inverse mapping F: Y → en introduceren we een cyclisch consistentieverlies om F(G(X)) ≈ X te pushen (en vice versa). Kwalitatieve resultaten worden gegeven voor verschillende taken waarvoor geen gekoppelde trainingsgegevens bestaan, waaronder transformatie van verzamelmethoden, objectvervorming, seizoenstransformatie en fotoverbetering. Er worden zoveel mogelijk scènes geselecteerd die vergelijkbaar of vergelijkbaar zijn, terwijl ze verschillende kenmerkende afbeeldingen bevatten. In dezelfde scène bijvoorbeeld de camera is vies en niet vies; de camera heeft foto's van regen en geen regen. Uit de trainingsresultaten kunnen we zien dat als de twee geselecteerde afbeeldingen te verschillend zijn op de locatie, de andere meegeleverde functies te veel van invloed zijn op het trainingseffect en de kwaliteit van het genereren van afbeeldingen. En als de beelden die zijn gegenereerd op basis van de geselecteerde vergelijkbare scènes van acceptabele kwaliteit zijn, wordt de impact van gegevensverbetering weergegeven in afbeelding 3.

Figuur 3 Verbeteringseffect dataset
Bovendien gebruikt dit artikel ook een oversampling-methode om de dataset uit te breiden, gecombineerd met het YOLOV3-netwerk, wordt het geleverd met middelen voor gegevensverbetering, willekeurig bijsnijden van pakketten, willekeurig omdraaien, chroma-transformatie en andere bewerkingen;
De gegevens worden effectief uitgebreid om het aanpassingsvermogen van het algoritme te verbeteren en een grotere robuustheid te bieden om objecten te detecteren in de implementatiefase van praktisch gebruik. Om echter onderscheid te maken tussen de linker en rechter booghoek, zijn de schakelaars voor willekeurig omdraaien en draaien uitgeschakeld in het algoritme van dit artikel.
2.3 Optimalisatie van het herkenningsalgoritme op basis van het YOLOV3-netwerk
Het backbone-gedeelte van YOLOV3 maakt gebruik van de Darknet53-structuur van de auteur, die de problemen met het verdwijnen van de gradiënt en de explosie van de gradiënt kan oplossen door convolutioneel neuraal netwerk (CNN) en reststructuurnetwerk (ResNet) te combineren, waardoor de training van diepe netwerken mogelijk wordt. Bovendien hoeft het algoritme de kandidaatboxen niet vooraf te berekenen. Toch verkrijgt het de a priori BondingBox door te clusteren, 9 clusters en drie schalen te selecteren en deze 9 clusters gelijkmatig over deze drie schalen te verdelen. Vanwege het schaalprobleem is de nauwkeurigheid van het YOLO-algoritme echter niet de beste onder de doelherkenningsalgoritmen, vooral bij de detectie van kleine doelen. Om de detectienauwkeurigheid van het YOLOV3-algoritme te verbeteren met behoud van een hoge snelheid, is de backbone van YOLOV3 aangepast. De specifieke methode is om de channel attention SE-module toe te voegen aan de resterende eenheid van darknet53. De structuur van de resterende netwerkeenheid voor en na de transformatie wordt weergegeven in figuur 4.

Figuur 4 Reststructuur SE-module voor en na wijziging
De SE-module is afkomstig van SENet, wat staat voor Squeeze-and-Excitation Networks, kreeg het ImageNet 2017 classificatiewedstrijdkampioenschap, wordt erkend vanwege zijn effectiviteit en eenvoudige implementatie en kan eenvoudig worden geladen in bestaande netwerkmodelkaders. SENet leert voornamelijk de correlatie tussen kanalen en filtert de aandacht voor de kanalen weg, wat de berekening iets verhoogt, maar het effect is beter. Het backbone-gedeelte van Darknet heeft in totaal 23 resterende module-eenheden. In dit document worden de originele Res-eenheden omgezet in SE-Res-eenheden voor sommige resterende eenheden. Om het detectievermogen van het YOLOV3-netwerk voor kleine en middelgrote doelen te verbeteren, bevinden de resterende eenheden die we hebben gewijzigd zich ook in deze twee takken. De algemene netwerkarchitectuur van YOLOV3 getransformeerd door de SE-module wordt weergegeven in figuur 5.

Figuur 5 YOLOV3-netwerkstructuurdiagram
In het herkenningsnetwerkgedeelte wordt YOLOV3 krachtiger gemaakt door up-sampling en cross-layer cascadering om drie verschillende schalen van detectieresultaten uit te voeren. In het ontwerpgedeelte van de verliesfunctie worden het doelvertrouwen, de categorie en de positie in één keer geleerd door een cross-entropie-verliesfunctie, en de verliesfunctie wordt weergegeven in vergelijking 1.

3. Analyse van experimentele resultaten
3.1 Introductie van de intelligente analyseserver van Tienuo
De meeste bestaande videobewakingssystemen in voertuigen hebben alleen videobewakings- en opslagfuncties, maar bieden niet de mogelijkheid tot intelligente online analyse. De hardware van dit document is geïmplementeerd met behulp van de ingebouwde intelligente analyseserver die is ontwikkeld door Shandong Tienuo Intelligent Co., zoals weergegeven in afbeelding 6. De host is uitgerust met Huawei's zelfontwikkelde Da Vinci-architectuur AI smart chip ATLAS 3000, die kan omgaan met innovatieve analysetoepassingen in de meeste scenario's en de decodering en intelligente analysetaken realiseren van maximaal 16 kanalen van 720p video. En de testresultaten kunnen in realtime worden doorgestuurd naar de bestuurderscabine of de monteur, zodat de testresultaten handmatig kunnen worden bekeken en de bijbehorende veiligheidsmaatregelen kunnen worden genomen. Dit artikel gebruikt deze hardware om een rekensnelheid van 60 fps te bereiken bij het uitvoeren van een videokanaal met één camera. De gelijktijdige analyse van 4 kanalen van meerdere video's kan ook zorgen voor een berekeningssnelheid van 25 fps, wat de vraag naar real-time intelligente analyse van meerkanaals video kan realiseren.

Afbeelding 6 Intelligente analyseserver en interfaceschema
3.2 Resultaten identificatie pantograafstatus
Om de veiligheidsstatus van pantografen te detecteren, stelt dit artikel zijn eigen dataset voor de veiligheidsstatus van pantografen samen, die 2388 afbeeldingen bevat van verschillende vormen van pantografen, waaronder pantografen in normale toestand en pantograafbewakingsbeelden in abnormale toestand onder verschillende werkomstandigheden. De gelabelde dataset wordt getraind met behulp van het darknet-framework en het trainingsproces wordt getoond in figuur 7. Uit de figuur blijkt dat het trainingsverlies stabiel blijft na 12.000 iteraties en dat het model in een lokaal optimum kan vallen. Het leertempo wordt eenmaal bij 20000 iteraties aangepast en het verlies daalt tot onder de 0,1. De verbetering in rekennauwkeurigheid vanaf 20.000 iteraties is niet significant, en de bijbehorende mAP-grafiek laat een klein verlies zien in het generalisatievermogen van het model. Om rekening te houden met het trainingsverlies en mAP,

Figuur 4 Trainingsproces identificatie veiligheidsstatus pantograaf
Om het getrainde model in te zetten bij de intelligente analysehost, moet het getrainde model worden geconverteerd naar het om-formaat dat wordt ondersteund door de Huawei da Vinci-architectuur, met een klein verlies aan nauwkeurigheid in het conversieproces, maar alles binnen een acceptabel bereik.

4. Samenvatting en vooruitzicht
Dit document gebruikt het YOLOV3-algoritme om de veiligheidsstatus van pantografen te detecteren, inclusief structurele afwijkingen, vonken en het binnendringen van vreemde voorwerpen, door middel van real-time videobewaking, waarbij rekening wordt gehouden met de detectiesnelheid en tegelijkertijd wordt gewaarborgd dat de nauwkeurigheid van de detectie voldoet aan de vereisten van real-time tijd analyse. Het biedt nieuwe ideeën voor het gebruik van een intelligent analysesysteem aan boord bij een veiligheidsinspectie van stroomafnemers.